Introduction
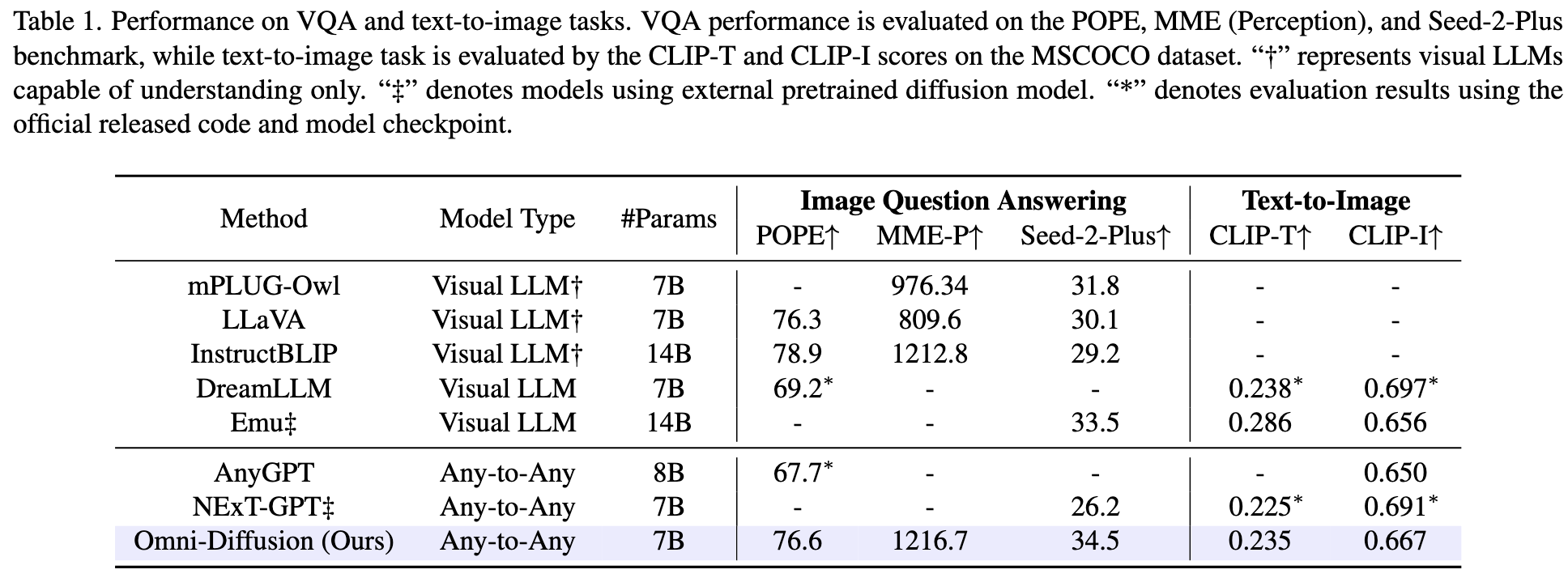
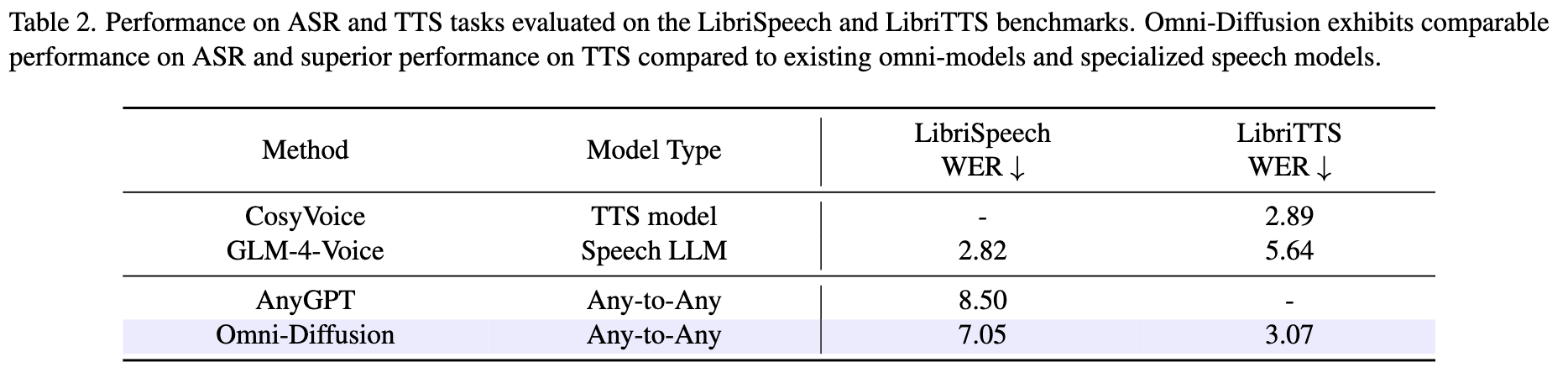
While recent multimodal large language models (MLLMs) have made impressive strides, they mostly employ a conventional autoregressive architecture as their backbone, leaving significant room for exploring effective and efficient alternatives in architectural design. We introduce Omni-Diffusion, the first any-to-any multimodal language model built entirely on mask-based discrete diffusion models, which unifies understanding and generation across text, speech, and images. Omni-Diffusion employs a unified mask-based discrete diffusion model to directly capture the joint distribution over discrete multimodal tokens. This approach enables support for not only bimodal tasks but also more complex scenarios involving multiple modalities. Our main contribusions are:
- First Any-to-Any Mask-based Discrete Diffusion Model. Omni-Diffusion is the pioneering any-to-any multimodal language model constructed purely using mask-based discrete diffusion model. It demonstrates robust performance on various tasks involving multiple modalities, illustrating the potential of discrete diffusion model in multimodal intelligence systems.
- Diffusion-Centric Training and Inference Framework. We develop specialized training and inference techniques tailored to the characteristic of mask-based diffusion models. For training, we implement an attenuated tail-pad masking strategy to facilitate variable-length generation and a three-stage progressive training pipeline for effective multi-modality alignment. For inference, we introduce position penalty to constrain generation order and enhance visual quality, alongside a special token pre-infilling strategy to improve spoken dialogue performance.
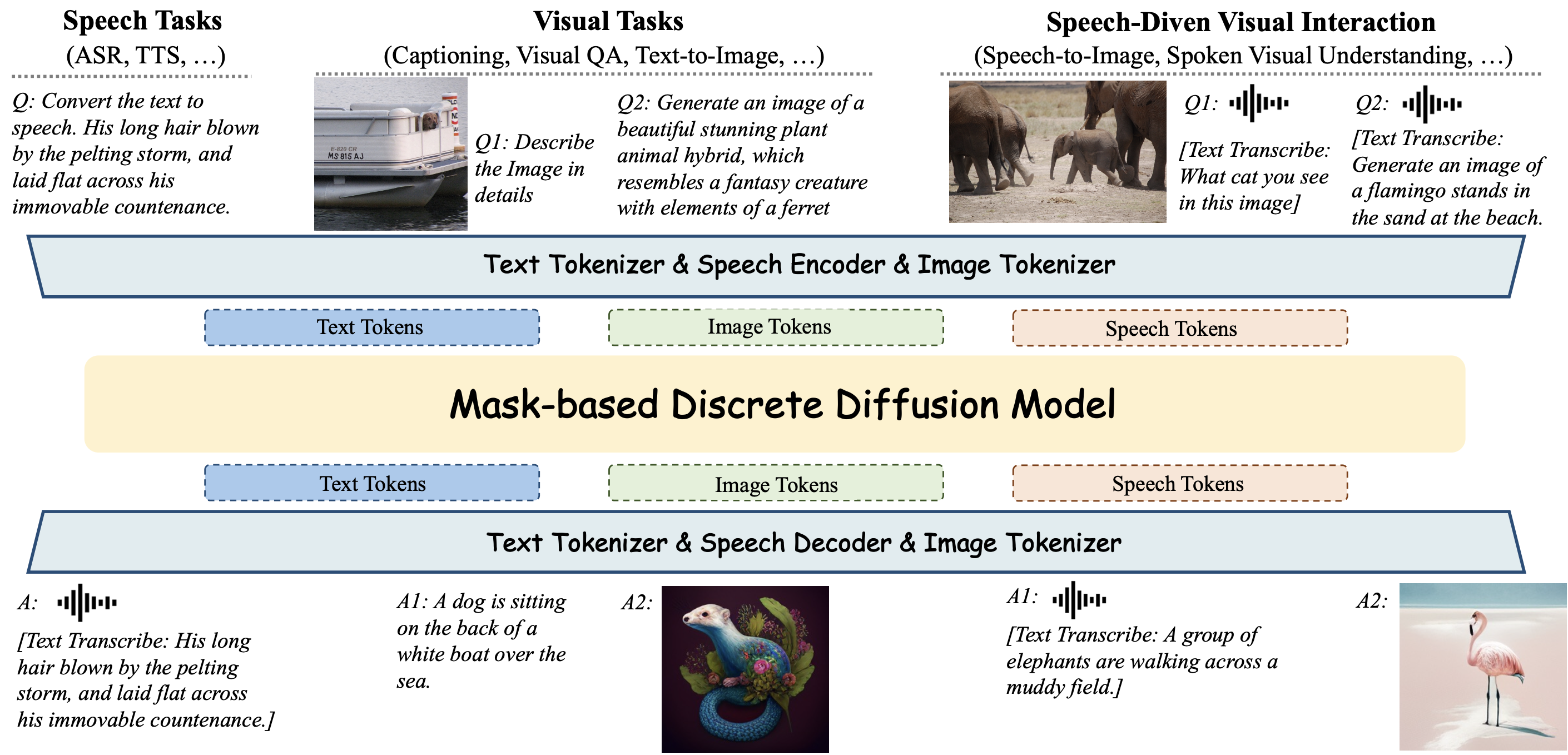
Figure 1: Overview of Omni-Diffusion.